|
HTML PLAIN reference V1.1 3. Parsing the documents 
|
Next: 4. The graphical user Up: HTML PLAIN reference V1.1 Previous: 2. Specification of the Subsections
3. Parsing the documents
3.1 Why Perl?The challenge is of course to parse documents efficiently, despite the large number of options allowed. Perl has been chosen as the implementation language. Unfortunately, not all Perl idioms and notations are easy to read (for a nice example see Section 3.3.1). Some idioms are very concise (and thus harder to read), and some expressions (especially built-in special variables and regular expression substitution) consist mainly of non-alphanumeric characters, which makes some lines of code look more like ASCII art than a programming language. This earned Perl the reputation as a ``write only language''. However, parts of the difficulties arise from slightly different notations, different operator precedence and data types which are not available in other languages (or only in a less flexible form). Another feature of Perl is that ``it occupies half of the English name space'' due to the huge number of built-in functions. Even without including Perl modules which introduce more names, it is possible to write poems in Perl (which even compile!), so there has to be something about it. You will find more about this in [Wal96, chapter 8]. Despite these minor disadvantages, Perl's features proved tremendously useful for implementing the parser. The parser heavily uses dynamic arrays, hash tables and more complex data types built upon these. The string substitution functions were of course invaluable. With ``old fashioned'' string libraries like C's string.h, the development would have been much slower. Regular expression matching and substitution allow very complex operations in just one line of code. There are other languages like Tcl which also offer regular expressions, but Perl's expressions have more powerful features than any other package I have found so far.For prototyping, Perl's underlying philosophy was also very helpful.
``Perl does not enforce private and public parts of its modules as you may have been used to in other languages like C++, Ada, or Modula-17. Perl doesn't have an infatuation with enforces privacy. It would prefer that you stayed out of its living room because you weren't invited, not because it has a shotgun.'' [Wal96]During the earlier development stages, when the interfaces still change now and again and it is not known which variables need to be accessed from outside, this is very useful. It saves the work of writing access functions for each variable that is used throughout the entire program. An example is the global line counter which hopefully gives more helpful error messages. It counts the line of the current template or document that is being processed. Because many modules have to access this variable, it is global. The alternative would have been to create an extra package (i. e. object) for this single variable, and an access method for incrementing it, and another one for obtaining its value. This is a nice design in theory, but not really needed in practice. Perl still supports true privacy and encapsulation, and this feature has indeed been used frequently, e. g. in the buffer package (Section 3.4.1), where the number of operations is bigger, and a few auxiliary variables are involved. Here, the keyword my makes sure that no other packages can mess up the contents of the buffer. It provides lexical scoping, which means that the variable is only visible within the current block (similar to auto variables in C). The block may be just a for loop, even a single statement, or an entire package. Us usual, Perl is rather open minded about these things. Probably the most popular line of code which involves the keyword my is:
|
|
3.3 Parsing the template and variables
First, the variable dictionary is read, and all variables are stored in a hash table. The same is then done with the template. All declared variables are replaced in the template while doing this. Finally, the file table is read.
3.3.1 The storage module
Since other languages do not have extensible hash tables as built-in data types, I encapsulated the storage of the definitions into a small Perl module. This very simple module handles all ``load/store'' requests, hence the names for the subroutines
![\begin{nohyphens}\par\begin{list}{}{
\setlength{\rightmargin}{\leftmargin}
\rag...
...~\$\{\$\_{[}0{]}\}\{\$\_{[}1{]}\}~=~\$\_{[}2{]};
\par\}\end{list}\end{nohyphens}](img10.gif)
The only difficulties arise from the Perl syntax. The operator precedence is crucial and can cause many hours of fruitless debugging if not known beforehand. The problem is the same for both subroutines.
First,
$_[0] is evaluated, the first argument, giving the location of the storage. The curly brackets {} around it are needed to prevent the Perl parser from evaluating $$_ first. This would use $_ as a pointer, which makes of course no sense. The leftmost $ dereferences the pointer to the hash table, and {$_[1]} takes the hash bucket with the second argument as the key, according to the common Perl syntax $hash{key}. A more precise explanation can be found in [Sri97, pp. 6 f.]:
``The expression involving key lookups might cause some confusion. Do you read$$rarray[1] as ${$rarray[1]} or {$$rarray}[1] or ${$rarray}[1]?
(Pause here to give your eyes time to refocus!)
As it happens, the last one is the correct answer. Perl follows these two simple rules while parsing such expressions: (1) Key or index lookups are done at the end, and (2) the prefix closest to a variable name binds most closely. When Perl sees something like
$$rarray[1] or $$rhash{"browns"), it leaves index lookups ([1] and {"browns"} to the very end. That leaves $$rarray and $$rhash. It gives preference to the '$' closest to the variable name. So the precedence works out like this: ${$rarray} and ${$rhash}. Another way of visualizing the second rule is that the preference is given to the symbols from right to left (the variable is always to the right of a series of symbols).Note that we are not really talking about operator precedence, since
$, @, and % are not operators; the rules above indicate the way an expression is parsed.''
3.3.2 The output module
This is a very simple module, allowing printing in colors (if the terminal supports this), which was helpful for early debugging stages. It also offers an interface for printing warning or error messages. In these cases, it checks for the global variables
fileName and line. If they are defined, they are used in the error message, hopefully helping to find the error.
3.3.3 Auxiliary parsing procedures
This package contains methods that deal with a single HTML tag or variable or several of them. It allows operations like replacing the tag(s) with the corresponding redefinition(s) (and the same for variables), overriding options within HTML tags and getting the correct relative path from a document to a target file. These functions are used by the template parser, the variable file parser and of course the main parser. Due to the importance of this module, I will go more into depth of some of its functions.
3.3.3.1
replaceTagsThis function replaces a number of tags with their redefinitions, if any. Tags that are not redefined are returned unchanged. The function
replaceTag is used to actually change the tags; replaceTags just splits up a string containing several tags into its components. This is usually trivial unless macros are involved. Because macros can in turn contain tags as arguments, a simple regular expression cannot parse them any more.
3.3.3.2
breakUpTagsBreaks up a number of tags into an array, which contains the content of the tags. Every element holds the text between the angular brackets. This function is used for decomposing the header and footer of the document, allowing a faster processing of it later on.
3.3.3.3
replaceVarsSimilarly to
replaceTags, this function checks a string for all possible variables (text in double quotes) and calls replaceVar which tries to replace them.
3.3.3.4
replaceOptionsThis procedure eliminates double occurrences of HTML options when an option should be replaced. For example, the redefinition for
<img> could be <img border="0" ... (and more options for the height and width). Assume that the user wants to override this with <img border="1" .... By simply inserting the new options at the beginning (after the tag name), the result would be
- <img border="1" border="0" ...
- $old =~ s/\s+/$new /; # add new arguments at front
while ($old =~ s/\s+(\w+)\s*=\s*(.*?)\s(\1)\s*=\s*(.*)/ $1=$2/i) {
# check for duplicate options and remove them
$tail = $4;
# restore rest of string (everything after argument name)
unless ($tail =~ s/^\s?\".*?\"\s?/ /) {
# remove first argument in quotes
$tail =~ s/^.*?\s/ /; # keep everything after space
}
$old .= $tail;
}
|
As the reader can now (after some regular expression acrobatics) see, this regular expression substitution solves almost the entire problem with one line of code. The only difficulty is the fact that the argument of the second option, which has to be removed, is not always enclosed in quotes. There are two cases:
- 1.
- The string is enclosed in double quotes
3.3.3.5
replaceTagThis procedure checks whether a tag has been redefined, and if so, replaces the tag with the new one. It calls
replaceOptions (see above) for taking care of duplicate options. The user may define a different meaning for a closing tag, e. g.
- /tt </tt><sans>
tt </sans><tt>
Another special property is the
<img> tag. In order to avoid problems with images that are not found, the special variables ``HEIGHT'' and ``WIDTH'' (see Section 2.3.2) are set to the undefined value before the options within the <img> tag are processed.
3.3.3.6
replaceVarThat part was fairly straightforward in older versions of the parser, but creeping featurism demanded its tribute. Now, every time when a file (a document or image) is recognized as belonging to a variable, a few special variables have to be set in order to be able to ``remember'' attributes like file name, size etc. later. Other than that (and taking care of options/switches), the code is still rather simple.
3.3.3.7
adjustPathThis procedure creates a relative link when given two absolute locations. The only peculiar line of code is
- "$path1\t$path2" =~ /^(.*\/)(.*?)\t\1/;
3.3.3.8
URLifyThese lines of code are a slightly extended version of the example subroutine in [Chr98, Section 6.21].
3.3.3.9 Other subroutines
The other subroutines are less important, and easier to understand (hopefully). The code is well documented, so all information can be found there.
3.3.4 The template parser
The template parser takes the template file and stores its content in a hash table. It uses references to the hash tables, but does not really know that the storage is organized as a hash table. Using the module
storage.pl, the structure of the storage is hidden.After stripping out empty lines or lines with only comments (starting with
// or #), the real parsing begins. C comments also require some care to be filtered out properly. The first tab (\t) character is searched, and it will separate the tag from its redefinition. The main challenge are definitions that go over multiple lines; they make the code more complicated. In order to allow multi line redefinitions, a redefinition is only stored when a new tag or entity is defined. In that case, the redefinition of the old tag is finished, and the old tag is stored. The redefinition of the new tag can then continue on the next lines.All in all, the module is pretty simple, and more information can be found in the source code itself.
$ and ^ are not treated specially, because these names can just be used as a hash key; Perl allows not only letters and numbers, but pretty much anything to occur in the hash key.
3.3.4.1 The hash tables for entity and tag redefinition
Redefined
&entities; are stored in entity => redefinition format, i. e. the ampersand (&)sign and the trailing semicolon are stripped out. Taking these two characters away makes the hash keys shorter. Similarly, HTML tag redefinitions are stored in tag => redefinition format, without the beginning and ending angular bracket. Any angular brackets in between are not removed. The two hash tables for entities and tags are separate, so there is no name space conflict after truncating the hash keys.
3.3.5 The variable file parser
This parser is much simpler than the template parser, because redefinitions going over multiple lines are not allowed. The only job it has to do is to split up the lines into the variable and the content and store them at a given position. It works in the same way as the template parser.
3.3.6 The command line argument parser
Using the module
Getopt::Long from the standard Perl library, parsing command line options is quite easy. The syntax is like
- GetOptions([option description]);
- 'syntax' => reference to variable
However, including this for all options from the configuration file involves a lot of typing and is error prone. There is also the danger of inconsistency. Therefore, a small program has been written which extracts the options from the configuration files and generates Perl code which parses these options as the output. The main loop is quite simple and looks like this:
- foreach (@lines) {
if (/\$(\w+) ?= ?'(.*?)';/) {
# string "$value = 'value';..."
if ($2 eq '0' or $2 eq '1') {
print "\"$1\" => \\\$$1,\n";
} else {
print "\"$1=s\" => \\\$$1,\n";
}
}
}
3.4 The document parser
The parser itself needs a few extra modules for its functionality. I will describe these first, and if the reader has not fallen asleep yet, he can then admire the description of the main module.
3.4.1 The buffer module
This module allows storing scalars (usually strings) in a buffer. This is needed for the second ``pass'' of the preprocessor, which deals with the header and footer of the document. It is also more efficient than a lot of write operations to a file, because all write operations happen in one run. The module offers one buffer and a lot of access functions, which allow appending a line to the buffer, getting, replacing, and inserting a line or several lines. Unlike the storage module, this one only supports a single buffer. However, it could easily be augmented to support multiple buffers, it that should be needed.
3.4.2 The macros
This package contains all the macro functions used. Note that even though they access all metadata through the IMP (see Section 2.5.2), they could also access variables or procedures directly, even though macros are run in a ``safe'' interpreter. This is because the safe interpreter allows access to the macro functions, which have in turn access to everything. The macro functions which can be accessed from the safe interpreter have to be defined beforehand. While they have full access to all Perl commands, it is not possible to smuggle in ``rogue code'' into the documents, because macros in these documents can only access predefined macros and IMP functions. Therefore, assuming that my macros are safe, macros cannot do anything worse than generating bad HTML output.
3.4.3 The file table loader
This package parses the output file from the file table generator (see Section 3.5). Due to the well-defined structure of that file, parsing it is trivial. After parsing it, some data structures are prepared in order to ease the work of the IMP (see Section 2.4). All IMP functions that deal with the file table are also contained in this module.
3.4.4 The parser (main module)
This module is the core of HTML PLAIN. It transforms the higher level documents and processes them as described in Section 2. First, a lot of preparation has to be done: the settings have to be read, storage has to be allocated, the template and variable files are read into memory via calls to these modules, a safe Perl interpreter is prepared, and the
mtime (time of last modification) of some key files is checked. Then, each document is processed.Before the text can be replaced, it has to be parsed first, though. This is the hard part. Unlike normal HTML, where all relevant entries are enclosed in angular brackets
(<>), there may now also be entities (&entity;) and strings enclosed in double quotes ("), representing a variable. This makes it impossible to just use split and dissect the string into all entities and non-entities. Instead, the parser needs several modes:
- 1.
- Standard mode. The parser is in this mode at the beginning or when reading plain text. It expects either a HTML tag or a string in double quotes. A missing ending double quote (before the end of the line) generates a warning here, since it may be used for quoting large parts of text.
- 2.
- HTML tag mode. No tags or entities inside tags (i. e. between the angular brackets)
are allowed, but variables can still show up. Strings in double quotes are likely,
either as simple arguments or variables.
A missing ending double quote generates an error here, for it is needed in a correct document. If the closing bracket (
| Term | Definition | |
| document | ::= | (plain_text | HTML_tag | variable)* |
| plain_text | ::= | (ASCII_character)* |
| HTML_tag | ::= | < (plain_text | variable)* > |
| variable | ::= | " plain_text " |
This simple grammar is (fortunately) context free, which makes it easier to
parse it. The parsing can be done with three important stages (as described
above), without any extra information (context). ``Magic tags'' (see Section
2.7 on page ![]() ) and macros make the
implementation a bit more complex, but the general algorithm remains the same.
) and macros make the
implementation a bit more complex, but the general algorithm remains the same.
3.4.4.1 First prototype parser
The first prototype has been written in Perl within about two hours, and was not fully optimized. The main loop is still the same in the final version. Most of the small subroutines in that module are very simple, and not described here.
3.4.4.2 Mode 1 - standard mode (unrecognized text)
The main loop for each line in the parser goes like this:
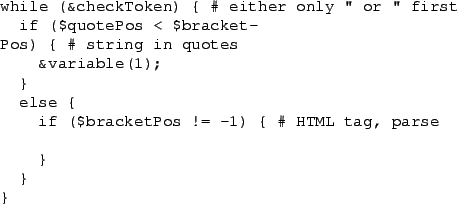
Every line is checked for an occurrence of an HTML tag or a quoted string, and if one of these is found, it is further examined. A check for HTML entities has also been added; since they can only occur in plain text, the check is not hard to implement.
3.4.4.3 Mode 2 - parsing HTML tags
This part is now too long to include the whole source code here. Most of the first part deals with the problem that line breaks are allowed within HTML tags, even though they should not be, because this leads to an ugly style and makes parsing harder. The syntax is not fully checked, e. g. errors like
The second part of the procedure dismantles the HTML tags into their parts: HTML within the angular brackets and options within double quotes, which may have to be replaced according to the variable dictionary (see Section 2.3). HTML tags have to be checked for occurring within the template, in which case they have to be replaced (see Section 2.2). If they are replaced, care needs to be taken for tags with options (like
<font face="Helvetica">). The option has to be filtered out when the tag is closed. After this step, we finally get a full HTML tag with options, and have to take further actions:
- 1.
- The tag is a ``magic tag''. In that case, the text up to the closing tag has to be read, and stored in the variable which has the same name as the tag itself (see Section 2.7). The whole string after the opening tag has then to be processed again.
- 2.
- The tag is a ``kill tag'', which simply means that everything the opening and closing tag, including these tags themselves, is removed.
- 3.
- We have a macro that has to be executed.
- 4.
- We have a simple HTML tag with no more bells and whistles.
3.4.4.4 Mode 3 (string in quotes)

This part is fairly straightforward. If a variable name (a string between double quotes) is found, it is replaced by its value. If the value (or the original string) happens to be a URL, it is ``URLified'', i. e. a
<a href="URL">URL</a> is inserted. If no closing quote is found, a warning is printed. In most cases, these warning can be ignored (e. g. in quotations that go over several lines).
3.4.5 'If' evaluation
There are two lists involved with if evaluation:
@ifReturn and @ifState. The first one corresponds to the list of return values of nested 'if's, the second one notes the position of the parser within a tree of 'if/then/else' statements. See Table 3.3 for the values that an element of @ifState can take.
|
Both lists are initialized with the single element -1, making an easier check (see below).
An example makes it clearer (see Table 3.4). The table shows the states after the statement has been evaluated.
|
As one can see from this table, the actions to be taken when a statement occurs are clearly defined. Table 3.5 shows an overview. The example does not show what happens if no 'else' statement occurs. Because an else statement only changes the first element of @ifReturn but does not change the number of elements, the states are still consistent without having an 'else' clause. Also, due to the way that both lists are defined, an arbitrary level of nesting can be allowed.
It is important that the lists are properly initialized, and that the list
@ifState always contains at least one element. This should be tested before an 'endif' statement is evaluated, in order to prevent the list from becoming inconsistent if an 'endif' statement occurs without a corresponding 'if'. Also, after parsing a document, the list can be checked for missing 'endif' statements in the same way. When an 'else' statement occurs, the first element of @ifState cannot be -1 -- otherwise we have an error as well.
|
3.4.5.1 Optimizing the evaluation
By using '-1' as a special value for
@ifReturn, denoting ``outside any if statements'', we can
- keep that list non-empty
- get an easy check whether a line should be included or not -
3.4.5.2 Implementation issues
There is still a small problem left: if all lines are ignored until the 'else' or 'endif' is found, these statements themselves are ignored, too. Therefore the check for 'else' or 'endif' statements has to be made in the main loop (for each line), making the code harder to read. A check there is much more efficient than after parsing each line, though.
3.5 Maintaining the file table
The basic task for this program has been outlined in Section 2.4.1
on page ![]() . There are currently three different
file types supported by this program:
. There are currently three different
file types supported by this program:
- 1.
- HTML files. In that case, the title is extracted (which is any string between two regexp patterns), and the file table entry consists of the title, the full file name, the file size and the content level (see Section 2.2.6).
penguin.gif 257x303+0+0 DirectClass 16335b GIF 1
If the user has a similar program, of which the output contains the information "widthxheight" after the first space, he may use that program instead. No guarantee is given that the file table will still be correct then. If someone has a GPL'ed Perl module that can find out the size of a JPG or PNG image, I will gladly include it :-)
3.6 Checking for dependencies
So far, only a rather simple (but effective) dependency check is implemented: if any of these configuration files (
3.7 Converting existing pages
The converter takes an existing page (which may also be the output of HTML PLAIN) and tries to ``reverse engineer'' it given a variable file and a file table. The goal is to reconstruct as much of the higher level information as possible. Because the syntactic structure is lost after parsing (and also in normal documents), the variable contents do no longer appear in double quotes and are harder to find. The only way to convert pages is to search in each line for every possible variable content and link from the file table, using a very big pattern for pattern matching. This makes the program rather slow.
Fortunately, Perl does a pretty good job at pattern matching, so the program is not too slow for smaller pages (converting larger pages is a very hard task anyway, because redundant HTML code among several pages is usually no longer fully consistent). Unfortunately, the relative links are different for each document, so the pattern matching string for relative links has to be rebuilt for each document.
If a pattern matches, the converter simply looks up the reversed variable and file tables and replaces the string. Reversing a hash table is quite simple in Perl, because
- %newhash = reverse %oldhash
- key1, value1, key2, value2, ...
For the file table, the value is a reference to an array with a set of values, so the reversion of the hash table has to be done manually by iterating over each element in the hash table, using
foreach (keys %hash). The full file name is extracted from the array and converted to a relative link, which is then used as a key for the hash table.For all hash tables, a string has to be generated containing each key as an option for a pattern matching string. This string, which may be quite long, is then used to scan through the document and trying to reconstruct as much as possible from the higher level HTML code. In the case of file names and variables, this works quite well. For tags, the problem is more complex due to options occurring in tags, which make the search much harder. In the first version of the converter, redefined tags are not yet converted back to ``higher level'' tags.
![]()
![]()
![]()
![]()
![]()
Next: 4. The graphical user
Up: HTML PLAIN reference V1.1
Previous: 2. Specification of the