|
HTML PLAIN reference V1.1 2. Specification of the HTML extension 
|
Next: 3. Parsing the documents Up: HTML PLAIN reference V1.1 Previous: 1. Introduction Subsections
|
| tag or entity | redefinition |
The tag may be already defined previously in the document; this allows recursive definitions. Of course this function should be used with care. The tag and the redefinition are separated with a tab
(\t) character. Everything behind a second tab character is regarded as a comment and ignored. Using a simple whitespace character would have the disadvantage of not allowing redefinitions of tags that include options, like <td nowrap>. No reasonable HTML text needs tab characters, so it can be used as a separator. Of course tabs are often used for indenting HTML code, but formatting of HTML code can be done with spaces as well (even though this is a kludge compared to tabs). The HTML code for templates should not become too complicate, so indentation will not be needed.New tags do not have to use the ubiquitous angular brackets; if these are missing as the first character (or last one, respectively), they are inserted automatically. Since only HTML tags are to be replaced, they have to be replaced by other HTML tags, so this rule can be applied. An exception is a HTML entity; if the redefinition starts with an ampersand sign
(&), it is of course not enclosed in angular brackets.
2.2.1.1 Comments
Comments will allow all people who are ``ASCII hackers'' to include their comments more easily. The GUI editor supports short comments at the end of the line, but cannot offer the wide variety of comments that is possible.
A comment can start with a hash symbol
(#) like in Perl or two slashes (//) like in C++. Longer comments can be written in C style, like in /* comment */. Comments are only allowed in the third column, except for C comments, which usually go over multiple lines.
2.2.1.2 Variables
In the redefinition part of the template, variables can be used. They are enclosed in double quotes
("variable name"), and their content is looked up in the dictionary (see Section 2.4).
2.2.1.3 Multi line redefinitions
If a definition does not fit into a single line, it can be continued on the next one. The first column is left empty, and the second (or first non-empty) column contains the continued text from the previous line. The line breaks will also appear in the final HTML text, unless a backslash
(\) is used to combine two lines into one (like in the C preprocessor).
2.2.2 Overriding options
If there is a default appearance of a tag, e. g.
<body color="#000000">, and the document itself contains the same tag with different or more options, these will override the options from the template. This allows the author of the page to override the settings given in a template, if this should be necessary. Any options occurring in either the template or the document, but not in both files, are used in the compiled version of the document.
2.2.2.1 Have the template options always override settings from a document
Sometimes, the opposite behavior from the one described above is desirable: a template option should always have precedence over the document. This can be to enforce a uniform style over inconsistent pages, or to use a JavaScript function for all links. The latter can be tremendously useful for pages that have multiple frames, which need to be updated when a link is used.
In order to get this behavior, the comment for the tag defined in the template must start with a
"!". This will look like a Unix-shebang comment if the template is viewed in an ASCII editor such as vi. The GUI tools do not yet specifically support this feature (e. g. by a check box for each tag), but will do so in a later version. An example shows this:
- href <a href=javascript:link("LINK")>"NAME"</a> # default look for links
aa <a> # for <a name=...> tags, use <aa=...> because <a> tags are replaced with javascript
a <a href=javascript:link("LINK")> #! always overrides document
If you still want to use some ``normal'' links, you now have to use a little trick, e. g. by defining an
<aa> tag in the template. The middle definition does this and allows you to tell explicitly if you want a standard link, by using <aa href> or <aa name>. Note that this definition has to be in the template prior to the redefinition of the <a> tag, because HTML PLAIN would otherwise assume that it was a recursive definition (i. e. an alias).
2.2.3 Special tags
2.2.3.1 ^ and $
^ stands for the beginning of a page, and $ for the end of it. These definitions are quite intuitive for people who have used regular expressions under UNIX before; there, these characters mark the beginning of a line (or the end of it, respectively). Here, their meaning is the same, just on a higher level. The parser automatically breaks up the set of tags defining ^ and $ into multiple lines, internally using an array.
2.2.4 Custom closing tags
Sometimes it is not possible to use the opening tags given, without options, as a closing tag. For example, in the case of nested tags, the closing tags have to appear in reverse order. Therefore the user can define a closing tag in a template which will be used in that situation and work like any other tag with a unique name.
If no such closing tag can be found, the preprocessor uses the opening tag after stripping the options. The order of the closing tags is reversed, so a custom closing tag should usually not be needed.
2.2.5 Example

2.2.6 Differentlevels of content
The definitions shown above are suitable if all pages are in the same ``level'' (content wise). However, It does not yet have any notion for the level of a content, making it impossible to generate different versions of ``navigation bars'' depending on how deep in the ``tree'' of a page the user is.
Depending on their position on the ``navigation tree'', pages have different
"levels" of content, according to their depth in the tree.
The depth can be calculated as
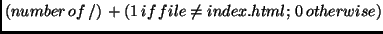 .
Slashes in the absolute path (before the document root) do not count. This formula
looks (and is) cumbersome, but an example shows that this definition is quite
intuitive:
.
Slashes in the absolute path (before the document root) do not count. This formula
looks (and is) cumbersome, but an example shows that this definition is quite
intuitive:
|
In this example, it is presumed that the page is well organized. Leaf nodes are HTML files, non-leaf nodes a directory (with an index.html for an overview). The depth of a document is (the number of extra /s in their path), where ``extra'' means relative to the main page. If the file is not index.html, the depth is one higher.
This definition maps directly to a tree (or ``site map'').
The tree, should, in this example, look like Figure 2.1. Of course a HTML version cannot fully reproduce the graphical representation.

Generally, only a part of the tree is shown; all nodes with a depth between (current depth-1) and (current depth+1). If the depth is greater than the current depth, nodes are only shown if they lie within the subtree that has its root at the current node. Figures 2.2 and 2.3 show two examples.


Usually a link to the top level (0) is always provided, either as part of the usual navigation links or at a special position. Therefore, an option to
- 1.
- always include
- 2.
- always exclude
Of course drawing a full site map based upon this is trivial, and the macro is not too hard to write. Filtering out the right part of the tree for obtaining a sub-tree is a bit harder, because the information is not represented as a tree, but simply as a list of strings; however, these strings contain enough information about their position in the tree.
2.2.7 Using macros in templates
The use of a macro is needed for more complex functions, such as the automatic generation of a footer. Redefinitions that contain a macro start with a
% sign. Like this, a possible redefinition for a footer could be

The word after the
% sign is the name of the macro that is called (just a Perl subroutine), the rest are the parameters passed to it (they have the same syntax like normal variables, see Section 2.3). LEVEL is the ``depth'' (see Section 2.2.6) of the current document in the tree of all documents. The last three arguments define the look of the image map. You can read more about macros in Section 2.5 on page
2.3 Variables
Variables contain either some constants that are used throughout the document (but not as HTML replacements) or symbolic references to filenames. This eliminates the need of tracking file names when they change and also makes it possible to use abbreviations for long names, which are later expanded into their full name. The most common use will definitely be for replacing filenames (see Section 2.4.1). Variables are case sensitive (unlike tags redefined in a template).
2.3.1 Order of replacements
- 1.
- file names
- 2.
- special variables (with results from filenames), document defined variables and variables from the dictionary (see Section 2.4)
- 3.
- environment variables
The second try is to find a matching name in the main variable table. That table contains all normal and special variables (see Section 2.3.2) and the content that has been found within the ``magic tags'' (see Section 2.7). In order to prevent name clashes, the user should refrain from having all uppercase names in his own documents and templates, even though people using AOL may find this very restrictive.
If the first two lookups (file names and variables) yield no result yet, the parser tries to find a matching variable name in the environment variables. This mechanism allows for setting some variables within shell scripts that call the parser. If no one of these three lookups are successful, the unchanged string, including the surrounding quotes, is returned.
2.3.2 Special variables
There are some special variables whose meaning is ``hard coded''. They are all written in CAPS and help to reference some properties of the current variable that is being replaced.
- [NAME]File name that is replaced.
- [LINK]The correct link to that file. With version 1.1. or higher, this also works with links including
- alt=\""NAME" ("SIZE")\"
Another very important aspect is the fact that the filename has to be the first evaluated argument, otherwise the variables SIZE etc. will refer to the previous file. There is no check being made for a valid return value.
2.3.2.1 Assignments to variables
As an alternative to definitions by ``magic'' HTML tags (see Section 2.7), a simple variable assignment such as
- <"title" = Our products>
2.4 The dictionary
The dictionary contains all symbols and names that should be used instead of filenames and URLs, for it is the key concept of HTML PLAIN to prevent the user from having to memorize filenames (and their paths, which can change). All instances of words within quotes
The syntax of the variables is simple: any combination of letters, numbers and underscores
(_) is allowed. Other characters such as punctuation characters are ignored. For references, the exact name of the page has to be used. By explicitly specifying the <a href=...> tag, the full flexibility of the linking tag can still be maintained. Variable redefinitions may contain other variables if they have been defined before. There is such a case in the example (see Section 2.4.3). For symbolic file names, spaces in the name are also significant.
2.4.1 The file dictionary
The format is very similar to templates (Section 2.2 on page
![]() ).
).
2.4.1.1 Definition of files and documents
One part of the dictionary contains all references to the files and images used in the HTML documents. These are generated automatically as far as possible (more about that on Section 2.4.4). When the HTML files are built, it is assumed that all references are correct. Therefore, the file table has to be up to date before the preprocessor starts.
When a variable (i. e. any strings within quotes) is encountered during the build process, the file dictionary is first checked. There are three different cases in which a quoted string may appear:
- 1.
- Without a surrounding HTML tag. The program then just guesses the usage of the
file.
- (a)
- If it is a HTML document, it is assumed that the string stands for a link. The proper (relative) link is inserted then.
- (b)
- If it is an image, the proper HTML tag is inserted. The settings (border, alignment etc.) can be specified in the template under
This overrides the standard behavior. SIZE is a special variable here (see Section 2.3.2), which allows to include extra information like the file size of the referenced document.
The file dictionary contains the absolute location of all files, together with their ``content depth'' (see Section 2.2.6). It is used during the build process to look up the filenames, which are then converted to relative URLs.
2.4.2 The variable dictionary
The variable dictionary contains the definition of symbolic constants such as
"company". This is essentially the same like the redefinition of HTML tags, but since it is semantically not an HTML tag, it belongs into the dictionary. If a variable is found in the dictionary, it is replaced with its value.Because longer comments should not be required, C style comments
/* comments */ are not allowed. However, Perl or C++ style comments at the beginning of a line are filtered out correctly.
2.4.3 Example
2.4.3.1 File dictionary
- About Us about/ 2
About "About Us" 2 # has been defined before
nice_image nice_image.gif
2.4.3.2 Variable dictionary
- company Artho Informatik # :)
manager Cyrille Artho
2.4.4 Maintaining the file dictionary
While the variable dictionary is maintained manually (either by editing the ASCII file or with the specialized editor), the file dictionary should be built up automatically as far as possible. The program
"plainfiles" deals with this problem. It checks all documents that lie within a specified directory and scans their content. It uses the Perl module File::Find which is provided with any modern Perl distribution. Unfortunately, this module cannot follow symbolic links to directories, so all images have to be kept within the ``root'' or ``pages'' document tree. This makes it a bit harder to upload all pages easily, because the images have to be uploaded from the ``pages'' directory instead of the ``upload'' directory. However, it is possible to create a symbolic link in the ``upload'' tree of the documents. There is no option yet to specify that the file table generator should search the upload tree for images or binaries. This will be added later, as it is very important for non-Unix users, since they have no symbolic links in their file system (serves them right).
2.4.4.1 Overriding the alphabetical sorting in the macros
If you want some documents to appear on top of lists generated by macros such as
SiteMap, you can now use the optional sortingFile. This configuration entry gives the location of a file in the following format:
- search replace
search2 replace2
intro 0
final }
... ...
2.5 Macros
Macros contain some Perl code that will be executed; the result will be used in the HTML code of the parsed page. They are run in a ``safe'' Perl interpreter, which means that they only have a very limited range of commands - for instance, they cannot write to files unless they have special permissions. The concept is much like Java's, with the exception that it is much easier to allow some external functions or variables to be used.
2.5.1 How macros work
Macros start with a
% sign as the first character in the redefinition of a HTML tag in a template (see Section 2.2 on pageA line containing a macro may not contain any more normal HTML tags in the same line. The entire line (except for the final closing angular bracket) is interpreted as a macro.
It is very important to notice that the macro functions have to return their result as a string, and not print it to
STDOUT. This makes it possible to use all predefined Perl functions and new functions in the same way, and will prevent a lot of unneeded redirections of the standard output. It also eliminates the need of many print statements in macros. Even though it may look easier for novice programmers just to print out the results, the string concatenation function "." makes it very easy to emulate printing. For example, the code

appends another line to the string
$out. Because all strings in double quotes are interpolated, nobody will miss the option to use
except for the case when the variable that needs to be printed is an array. Then, the built in Perl function
sprintf has to be used, or a foreach loop to iterate over the array.
2.5.2 The IMP
Since macros cannot access any of the program variables without special permissions,
access functions had to be provided for these. The interface over which variables
can access metadata about the document is called the IMP = Interface for Macro
Programming. The IMP provides macros with everything they need to know, such
as the names of all files, their size or level.
|
2.5.3 Built-in macros
It is maybe the easiest way to learn how to deal with the IMP by looking at some provided macro functions. Because these functions are very powerful, they may not be always easy to understand. Here is a short description of them:
2.5.3.1 DumpArgs
This function just prints all arguments given. Use it for testing whether all variables have been correctly interpolated.
2.5.3.2 LinkTable
This macro creates a table with links to related topics. The arguments are given
in Table 2.3.
|
Except for the last argument, the meaning of the arguments is fairly straightforward.
The minimum and maximum levels determine how many links are shown (see Section
2.2.6 on page ![]() for more information).
The next four arguments control the appearance of the table. The last argument
is a combination of several bits for some options:
for more information).
The next four arguments control the appearance of the table. The last argument
is a combination of several bits for some options:
|
In order to get the required value for the argument, sum up 2n for all bits that need to be set, e. g. 20+22+23+24=29 for using all options. 4 is a good value for the mode (always link to root node), 0 is default.
2.5.3.3 MakeLinks
This function is very similar to the one above, but it creates a hierarchical list of links (basically a subset of a site map).
|
See Table 2.4 for a description of the modes. Mode bit 1 is used here; in the case where non-breaking spaces ( ) are used for indentation rather than list tags (e. g. <ul>, <dl>), these have always to be repeated from 0 on. 20 is a good value for the mode, which means that the links to related topics will turn out right, and the main page will always be among the links.
2.5.3.4 SiteMap
``SiteMap'' generates a complete list of all links, hierarchically structured, also known as a ``site map''.
|
This macro is a lot simpler, because there is no minimum or maximum level required, and each page appears on the list. The mode argument has two bits:
- bit 0: have the file size after the links included; usually the default value 0 is used (no file size).
- bit 1: don't include the separator before the first entry. Set this bit if you use something like a pipe character
2.5.3.5 Back
This macro generates a link to the parent page (the page one level higher in the site map tree whose child is the current page). Unfortunately this involves scanning all the metadata about the pages for the parent. This is the reason why the macros ``LinkTable'' and ``MakeLinks'' set the special variable ``BACK'' for the current page. This variable is cleared before each document is processed and holds the name of the parent page. If the macro ``Back'' finds the value to be set, it uses it and saves a few CPU cycles. Otherwise, it searches the whole file table for the parent page.
The only optional argument is a text to be included in the link, such as ``Back to''. You can use this text to link with both an image and text; a possible template definition could be
- <%Back('<img src="/images/back.gif" border="0"> ')>
2.5.3.6 Prev
This macro creates a link to the previous page within the same subtree in a site map. This means that a page higher up in the hierarchy will not be linked to (the macro will return an empty string), nor will there be a link to a different directory. The best thing to find out how this thing works is to try it :-)
There is also an optional argument, like in the macro
Back, for the link text that comes before the name of the page.
2.5.3.7 Next
This macro links to the next page within the same subtree in a site map and works otherwise like
Prev (see above for more information).
2.5.3.8 LinkTo
This macro generates a correct link to a variable of which the content is a file within the ``source'' tree. This can be used to get a correct relative link to binaries, in case they have an exotic extension which has not been specified in the configuration as an extension for binary files. The only argument is the file to be linked to. This macro is now deprecated and only included as an example for IMP calls.
2.5.3.9 Pictures
Sometimes a page with all pictures within one directory is needed (e. g. for screen shots). This simple macro takes all files within a directory and creates a table for them. The first argument is the directory, the second (optional) one is the width of the table in cells (default: 2).
2.5.4 Adding new macros
If a macro is too long to be included in one line of code (e. g. the template), it is recommended to add it to the
macros.pl file. Then its name has to be added to the configuration in order to allow the safe interpreter to execute the macro. Even then, malicious macros cannot do much more than screwing up the layout of the output page or force the preprocessor to quit (e. g. because of a syntax error). Unlike in a popular(?) word processor, macros do not have the full control over the computer they run on :-)
2.6 Other replacements
Other operations than the replacement of tags defined in the template and variables (see Section 2) is the replacement of absolute URLs (starting with
http://, ftp:// or mailto:) by a link, if this has not been done yet by the user. The same goes for e-mail addresses. There is not yet a way to override that behavior if a string that looks like a URL or e-mail address is not what it seems to be. However, the recognition of these strings is quite reliable, and I have not found a need to turn this feature off.
2.7 ``Magic'' tags
Sometimes, it is desirable to use information inside a document rather than within the template. This is implemented by giving the parser a set of ``magic'' tags that trigger a special behavior: before the content between that opening and closing tag is evaluated, the parser first searches through the file for the ending tag and then sets the variable with the name of the ``magic'' tag to the string between the tags. In the configuration file, a set of possible ``magic'' tags is specified. This may seem awkward but it is the only way to prevent having either two passes when compiling the files or maintaining a huge lookup table for any content between any opening and closing tags (not to mention the tags that will never be closed, such as
<hr>). This would have been an overkill for such a feature that is not that important.After setting the value of that variable (and potentially overwriting a user defined variable from the dictionary), parsing goes on, back after the opening tag.
E. g. if
- <title>Hello, world!</title>
These magic tags can be used to include information from the document (such as the title) within the header and footer in the template2.1.
2.8 Preprocessor directives
In the first line of a document, special options can now be specified in order to change the behavior of the preprocessor. This is sometimes more elegant than changing the options, and allows the inclusion of features that would otherwise not be possible to implement.
2.8.1
skip
If the first line of the document is
- <!- skip ->
2.8.2
foreach
Sometimes an HTML page containing variables should generate a set of output pages. An example is when there is a page about financial data for each year. The web master generates a document holding all information such as number of each product sold, costs associated etc. in variables. The parser should then generate a set of output files based on special supplementary data files (which are variable dictionaries).
This is a very powerful directive. The same keyword as in Perl has been chosen, which may make it easier to remember, but also easier to confuse. The first line looks like this:
- <!- foreach finance*.data year ->
In order to be able to refer to the value of
* (the year in this case), an optional second parameter specifies the name of the variable containing that value. This makes it very easy to design a page with ``financial data of year xy'' and use that page for generating pages for each year.The format of the data files is exactly like the variable files. Indeed, some values are expected to be inside. The ``startPat'' option (see Section 5.2) has to contain a single HTML tag, and the tag name has to be defined as a variable as well. For instance, if the ``startPat'' option is set to
<title>, the variable ``title'' has to be found in each *.data file. It will then be used in the document title, if that title contains the variable ``title''. A simple example makes this less obfuscated:
2.8.2.0.1 finance_template.html
This is the ``sub template'' which generates a set of pages with financial data. Its first line is
- <!- foreach finance*.data year ->
- <title>"title"</title>
2.8.2.0.2 .data files
These files are simple variable files (see Section 2.3 on page
![]() ), containing all values that are referred to in
), containing all values that are referred to in
It has to be noted that the old values of variables which are defined in the
data files will be overwritten and not restored later. This improves the performance
of the preprocessor, and should not be a problem if the names of the data fields
are chosen carefully. A more elaborate example can be found at Appendix A.1
on page ![]() .
.
2.8.3
if/else/endif
These preprocessor directives are quite simple to use. Their syntax is:
- <!- if (expression) ->
HTML text which appears if expression is true
<!- else ->
HTML text which appears if expression is false
<!- endif ->
The statements can be nested to any depth, like in any programming language. Because the 'endif' is compulsory, there can be no ambiguity in the case of nested statements. If more complex expressions have to be evaluated, it is better to include a short function in
macros.pl, which, unlike a normal macro, does not return a string with HTML, but either true or false.
2.8.4
include
The include directive provides an alternative to tag redefinitions. It is not more powerful than tag redefinitions, but may be more convenient. The syntax is simple, but allows many options:
- <!-[#]include [file|virtual=]"file" ->
``File'' may be a symbolic or a real file name (because the include file may not have the necessary tags to make it appear in the file table). If the include file has a tag like
<title>...</title> which gives it a symbolic file name, this tag is later filtered out.When using server side includes are used, the file may of course be dynamically generated (e. g. in form of daily updates), and a static inclusion is not the desired effect! Therefore, if an include file should be dynamic, it should not be present at ``compile time'', i. e. when
htmlplain is run. The program will preserve the old include statement, and proceed as if nothing had happened. If the simpler HTML PLAIN syntax is used, an error message is generated if the file is missing.Include pages are processed every time when they are included, which means that macros will always evaluate in the context of the page which has the
include statement. Special variables (see Section 2.3.2) such as ``SELF'' are not changed while the include page is processed. -- At this version, the include page is also processed, independently from being included somewhere, as a normal page, because the program does not check whether a page is included elsewhere. This may result in some unwanted output pages, and the ``hide'' configuration setting should include the file name of that page, in order to hide it in the site map.Include files can be as complex as any other HTML file, i. e. they can use all macros, directives etc. that other HTML pages can use. However, the
foreach statement does not make sense in this context (because that statement produces a set of pages, and include deals with a single page). If foreach is actually used in the include page, it has no effect when the page is included; however, it will still work as usual when the include page itself is processed. Nested includes are allowed.
![]()
![]()
![]()
![]()
![]()
Next: 3. Parsing the documents
Up: HTML PLAIN reference V1.1
Previous: 1. Introduction