|
HTML PLAIN reference V1.1 5. Example and test pages 
|
Next: 6. Summary and conclusions Up: HTML PLAIN reference V1.1 Previous: 4. The graphical user Subsections
5. Example and test pages
|
| Program | Function |
| wish config.tcl | Configurator. An alternative version is config2.tcl. |
| wish variables.tcl | Variable editor, needs configuration prior to usage. |
| wish install.tcl | Installation program. |
| wish template.tcl | Template editor, needs configuration prior to usage. |
Under Windows, some obscure configuration has to be made in order to make the
Tcl files launch the interpreter, since the ``She-bang'' notation
5.1.3 The Perl programs
Only two Perl programs need to be run (preferably with a correct path in their first line):
plainfiles and htmlplain. Again, they require config.pl (the file containing the configuration) to be set correctly. The program plainfiles has to be run first, and every time when new pages are created. Htmlplain has to be run in order to obtain a preview for all compiled pages, and of course before uploading the documents. It is recommended to set up the configuration first, then design the template, and then go on with the HTML documents.A third program,
converter, is optional, and allows existing pages to use some of HTML PLAIN's features.
5.2 An example configuration
See Section 2.2.5 on page ![]() for an example template. The full (long) listing of all files is shown at Section
A.1 on page
for an example template. The full (long) listing of all files is shown at Section
A.1 on page ![]() .
The example template that comes with the program almost identical. The example
configuration looks like this (only the most important entries are shown):
.
The example template that comes with the program almost identical. The example
configuration looks like this (only the most important entries are shown):
In case the short explanations are not clear enough, here are more details about some configuration entries:
5.2.0.1 Variable names
These are the ``magic tags'' of which the text between the opening and closing tag will be stored in a variable of the same name. Now this sounds even more complicated than the short version :-) It means that if you have a tag like
<title>Text</title>, it will set the variable ``title'' to ``Text''. This will only occur if the tag has been specified beforehand, and the closing tag should come immediately after the tag (i. e. there should be no more tags in between such as in <table>).
5.2.0.2 Root, output path
These should be absolute directory names. The tilde is not expanded, and relative links do not always work. Don't worry, the web page that will come out will have relative links, not absolute ones.
5.2.0.3 Search/replace pattern
Sometimes it may be useful to have a search/replace function on the input text before it is processed. Regular expressions in Perl syntax are supported, but references to matching text are not (it never worked when I tried it). Usually this will be used to delete some text.
5.2.0.4 Fast header/footer
Usually a very complex algorithm is applied in order to combine the document with the template header. If the document contains no meta tags and is written from scratch (i. e. all markup language is in the template), then this option can speed up processing the documents.
5.2.0.5 Glue header/footer
For some tags (usually all tags after
<body>), it is not possible to tell whether they are still part of the header, or whether they are part of the document itself. This goes for any ``generic'' tag such as <br>, <p>, <img> etc. In order to prevent the preprocessor from overwriting these, a fixed point has to be known, from which point on no line of the document will overlap with the header. Unless the template uses more unusual tags such as <blockquote>, which may also appear (redundantly) in the documents, this option should not be changed. The reason for the complex algorithm is to allow pages to have meta tags (for search engines) which cannot be set by templates, and for being able to include automatically generated documents such as latex2html output. And behold, this actually works pretty well!
5.2.0.6 Start/end pattern
These patterns determine where the symbolic name of the document will be found. If you do not want it to appear in the document, use your own comment tags for it, such as
<!- name -> and <!- endname ->. I found it convenient to use the <title> tag because XEmacs always includes it in empty HTML pages, and you just have to enter the title in order to fill it in. If you want to use a different title later on, it is recommended to include the comment line
- <!- <title>old title</title> ->
5.2.0.7 Size divisor/suffix
This allows it to include size information. Some lame editor includes the information up to the byte, which is not only hard to read but usually irrelevant. In this program, you can change the unit in which it appears. Set the divisor to '1' and the suffix to nothing or 'bytes' if you want to have the exact file sizes, otherwise use the example value.
5.2.1 Command line arguments
Command line arguments can be used to override settings from the configuration file. They always have exactly the same name like the entry in the configuration file and are preceded by
-. For instance, in order to override the ``root'' setting, use
- htmlplain -root=[new document root]
5.2.1.1 Other command line arguments
Besides all options from the configuration file, there is also the option
-o, which is equivalent to -outputPath. Another option not occurring in the configuration file is -all. Setting this flag disables any dependency checking and forces the preprocessor to generate each document newly, even if it has not been updated since the last run.Parameters without switches are interpreted as input files. Unless a file matches one of the pattern(s) given, it is not processed. This allows the use of Makefiles to check dependencies. Note that the
-all option still needs to be specified if the built-in dependency checking should be disabled.
5.3 An example page
The example page uses the configuration from above (Section 5.2). The template is rather simple, in order to show the most outstanding features:
5.3.0.1 The template
The first line redefines the ugly
<hr> tag as a line break. The second line defines a fancy font. The third line is more interesting, as it is a special header tag (also see Section 2.2.3 on pageThe next tag,
$, is the footer tag. It works like the header tag. The <img> tag also has a special importance, because it defines the appearance of all images which do not use tag options to override the template settings. Therefore, the default options should be used sparingly. Note how the variables in capital letters refer to special properties of the image (also see Section 2.3.2 on page
5.3.0.2 The variables
The variables are mainly used for colors here, but they also show the use of referencing external URLs. Since you never know whether they change, you had better define a symbolic name. The tab characters are not properly reproduced here; they will appear differently in most editors (such as vi).
5.3.0.3 The example pages
There are a few example pages that come with the current release. Both pages are using the XEmacs standard template, which is partially overridden in order to get a fully customizable page. They show the most important features:
With the example configuration, most of the bottom part is filtered out. The output looks like this:
The second demo page exploits some other features:
- 1.
- The
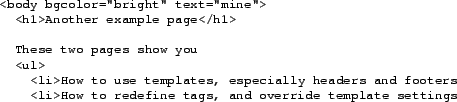
The output is a page with different colors than the previous one. The link back to the previous page appears at the correct place, and the image also has been replaced. These two pages show all important features of HTML PLAIN.
5.4 Writing the pages
The most important step is writing the template. It should contain as much as possible of ``recurring themes'' throughout all pages. The header and footer might be as simple as a ``complete''5.1 set of tags up to
<body> (or from </body> on, respectively), or they can contain a navigation bar, which is possibly generated by tables. In that case, the table tags that are opened in the header should be closed in the footer. Like this, a complex but uniform layout can be maintained throughout all pages.The task of writing the web pages is now much simpler. You do not have to bother about recurring content (such as navigation bars) in every page once you have written a nice template. In the page itself, just use the actual text that goes into each document. There is no need to repeat all the header tags. If you want to include meta tags, though, you have to specify the
<head> and </head> tags, too, in order to tell the preprocessor where to put the meta tags. You should also specify the <title> tags, as the are important. Other than that, you can use as little markup as line breaks, like in this example document:
- <title>This is an example</title>
<h1>Example</h1>
This document is for use in HTML PLAIN.
<br>
As you can see, the amount of HTML code
that needs to be written is very small.
5.5 Including
latex2html output
I found the program
latex2html quite useful, because it allows to have a fairly good representation of a postscript file in HTML form5.2. In order to use its output in HTML PLAIN, a few intermediate steps are needed. First, it is required to rename node0?.html to node 0?.html in order to get right order of all files in the site map etc.

is the wonderful shell command that does this job. Second, the hierarchy cannot get fully recognized since all output files have the same name (except for their number), regardless of their content level. Therefore that part of the site map will be flattened to a list.
The last step is to fix all the links inside the converted documents, because these still refer to
node01.html to node09.html. This is done with the short Perl script latex2htmlinc. In fact, the Perl script also does the file renaming. So you just have to run latex2htmlinc in the directory where the output files of latex2html are. That script accepts the command line switch -imgbug, which makes the program change all links to img[n].gif to img[n+1].gif. This is to work around a bug that I encountered with the latex2html output (before any other program is run); however, that bug may not always occur.It is important that
latex2htmlinc is only run once, as it will corrupt the files if run a second time. It also has to be run every time after latex2html was called.Because the output of
latex2html is not ``clean'' HTML, the preprocessor will complain a lot once the output from latex2htmlinc is included in a page processed with htmlplain. Fortunately, the HTML output of the first converter is still readable by browsers, and therefore all output messages are only warnings, no errors.
5.6 Uploading
It is intended that the pages from the ``output path'' are uploaded. In order to be able to upload the images as well, the program automatically creates symbolic links for each image found in the source tree. Because the program cannot follow symbolic links to directories, all images, binaries and HTML sources should be in the source tree. The file table program will create the necessary symbolic links in the output path for both images and binaries. On file systems with no symbolic links, a warning is issued; however, there is no alternative for symbolic links (of course the file could be copied, what a waste of space), so it is recommended that the file system is upgraded to a Unix-like file system that supports symbolic links.
5.7 Converting existing HTML pages
It is well worth using HTML PLAIN for existing pages, mainly for the sake of file management. While some aspects (such as templates) cannot be included anymore without some manual work, it is at least possible to replace all the relative links and variable contents with the symbolic names found in the HTMLPLAIN file table (see Section 2.4.1) and variable dictionary (see Section 2.3).
The converter takes the same configuration file as
htmlplain does, but it does not need all the options. In particular, the ``outputPath'' option is crucial, since the resulting files will be stored there. A second configuration file should then be used later on with htmlplain, where the former ``outputPath'' is the new ``root'' path. It is not recommended to work with the old documents after a page has been converted for HTML PLAIN, but it is of course possible.
5.8 Managing multiple sites
The macro file is installed is the program directory (
/usr/local/htmlplain by default). Therefore, if several users wish to create their own macros, they need write access to that file. In a later version, it may be possible to have a local copy of the macro file. Because the macro file is the most security sensitive part of the preprocessor, I thought it is better to install it such that only the superuser can modify it.The configuration file is user specific, by default in the home directory. This is also where the variable and template files should commonly be stored. However, a problem occurs when several separate pages for different sites should be made for one user.
In that case, the user should take advantage of the fact that ``local'' configuration files (within the directory where the program was started from) are ``preferred'' to ``global'' (in the user's home directory) ones. Therefore, for multiple pages, the user simply has to copy all configuration files into the document root for each site, and modify them accordingly. The parser should then be started from the document root of each site.
![]()
![]()
![]()
![]()
![]()
Next: 6. Summary and conclusions
Up: HTML PLAIN reference V1.1
Previous: 4. The graphical user